Peatükk 5 Tidytext ja tekstitöötlus
Selles peatükis teeme esimest tutvust tidytext paketiga, mis on loodud tidyverse stiilis tekstitöötluseks R-is. See pakett ei suuda teha kõike ja ei pruugi olla alati ka kõige kiirem, aga teeb siiski ära lihtsama tekstitöötluse, mida meil vaja võib minna. Kui tekib huvi juurde õppida, siis selle paketi enda juhend on siin https://www.tidytextmining.com/.
Kui me alustasime R-i programmi uuesti on tarvis kõigepealt sisse lugeda paketid.
tidytext pakett on tidyverse põhipaketist eraldi ning seetõttu tuleb eraldi sisse lugeda. Kui seda pole varem installitud, siis utleb ta ka installida.
Kui me käivitasime R-i uuesti, siis on meil vaja töötamiseks ka andmefail uuesti sisse lugeda.
## Parsed with column specification:
## cols(
## year = col_double(),
## rank = col_double(),
## votes = col_double(),
## artist = col_character(),
## song = col_character(),
## filename = col_character(),
## source = col_double(),
## lyrics = col_character(),
## language = col_character()
## )5.1 unnest_tokens()
Peamine käsk, mis aitab meil tekstidega R-is töötada on unnest_tokens(). unnest_tokens() võtab sisendiks ühe tekstitunnuse ning jaotab ta mingil alusel elementideks (tokeniseerib). Näiteks siis saab teha tekstidest sõnaloendi. Kui see on tehtud asetab ta iga elemendi omale reale, järgides tidy data põhimõtteid, et meil peaks olema üks vaatlusobjekt rea kohta. Lisaks eemaldab ta tekstist numbrid, kirjavahemärgid, suurtähed ning teeb muud eeltöötlust, et eraldada elemendid tekstist.
unnest_tokens() - muudab andmestikku nii et iga tekstitunnuse element oleks omal real.
Vaatame kõigepealt selle lihtsamat tulemust. Järgmine käsk võtab andmestiku tunnnuse lyrics, teeb selle elementideks (mis on vaikimisi sõnad) ning salvestab kõik ‘word’ nimelisse tulpa.
## # A tibble: 157,632 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et välän
## 2 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et külmetas
## 3 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ja
## 4 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et taivast
## 5 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et satas
## 6 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et lummõ
## 7 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ütle
## 8 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et mullõ
## 9 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et uma
## 10 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et telefoni…
## # … with 157,622 more rowsKui meil varem oli üks lugu tabelis iga rea kohta, siis nüüd on meil igal real üks sõna sellele kaasneva metainfoga. Ehk näha on midagi sellist.
# A tibble: 157,632 x 9
# year rank votes artist song filename source language word
# <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
# 1 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et välän
# 2 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et külmetas
# 3 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et ja
# 4 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et taivast
# 5 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et satas
# 6 1994 1 NA Ummamuudu Kõnõtraat lyrics-ummamuudu-konotraat 1 et lummõ Kuna me kasutame seda andmekuju korduvalt ja tokeniseerimine võtab iga kord veidi aega, salvestame selle töötluse tulemuse ja viitame edaspidi juba töötluse lõpptulemusele.
Selle tabeliga saame teha samasuguseid operatsioone kui edetabeliga enne. Näiteks võime võtta kõik sõnad, mis on ühelt bändilt.
## # A tibble: 6,809 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et hella…
## 2 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et luban
## 3 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et sind
## 4 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et hoida
## 5 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et ma
## 6 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et ja
## 7 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et käia
## 8 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et sind
## 9 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et linna
## 10 1996 4 1192 Smilers Tahan Si… lyrics-smilers-ta… 1 et peal
## # … with 6,799 more rows## # A tibble: 7,006 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et olen
## 2 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et tulnud
## 3 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et liiga
## 4 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et pikalt
## 5 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et teelt
## 6 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et tühja
## 7 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et maja
## 8 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et leids…
## 9 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et enda
## 10 1994 8 NA Terminaat… Torm lyrics-terminaator… 1 et eest
## # … with 6,996 more rows## # A tibble: 163 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et välän
## 2 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et külmetas
## 3 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ja
## 4 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et taivast
## 5 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et satas
## 6 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et lummõ
## 7 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ütle
## 8 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et mullõ
## 9 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et uma
## 10 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et telefoni…
## # … with 153 more rowsProovi ise! Vali välja üks artist ning võta tabelist välja ainult nende kasutatud sõnad
5.2 Sagedussõnastikud
Et sõnade valikutest midagi huvitavat teada saada, võime hakata neid loendama - ehk siis teha sagedussõnastiku.
## # A tibble: 19,046 x 2
## word n
## <chr> <int>
## 1 on 4401
## 2 ja 3311
## 3 ei 2872
## 4 ma 2705
## 5 kui 1980
## 6 sa 1551
## 7 see 1505
## 8 et 1492
## 9 me 1165
## 10 veel 1088
## # … with 19,036 more rowsNagu näeme, on enimkasutatud sõnad ka lauludes enamvähem samad kui keeles üldiselt. On, ja, ei, ma, kui, sa jne.
Me võime filtrite abil koostada ka sagedussõnastiku mõnele üksikule artistile ja vaadata neid ühekaupa.
## # A tibble: 1,635 x 2
## word n
## <chr> <int>
## 1 ei 219
## 2 on 189
## 3 ja 147
## 4 ma 146
## 5 kui 117
## 6 et 108
## 7 kõik 98
## 8 veel 71
## 9 sa 62
## 10 mis 56
## # … with 1,625 more rows## # A tibble: 80 x 2
## word n
## <chr> <int>
## 1 ära 15
## 2 su 14
## 3 tunnen 14
## 4 ja 11
## 5 ma 7
## 6 sinu 7
## 7 mullõ 5
## 8 telefoninummõr 5
## 9 uma 5
## 10 ütle 3
## # … with 70 more rows## # A tibble: 312 x 2
## word n
## <chr> <int>
## 1 ka 39
## 2 ja 29
## 3 ma 29
## 4 mina 29
## 5 sa 23
## 6 ou 22
## 7 nagu 18
## 8 kui 15
## 9 ei 13
## 10 siis 13
## # … with 302 more rowsProovi ise! Vali välja üks artist ning vaata nende enimkasutatud sõnu.
5.3 Stopsõnad
Leiame, et nagu ikka eesti keeles, on ka lauludes levinumad sõnad sidesõnad ja asesõnad ja muu selline. Nagu meil loengust läbi käis on siis tihti kasulik eemaldada stopsõnad, et saada selgemalt aru, mis laule teineteisest erinevad ja millest need lood räägivad.
Me võime kasutada ükskõik, millist tabelit sõnade loendina. Eesti keele jaoks on olemas hea stopsõnade loend siin http://datadoi.ut.ee/handle/33/78. Loeme selle sisse eraldi tabelina.
## Parsed with column specification:
## cols(
## word = col_character()
## )Nüüd on meil kaks tabelit ja me soovine neid omavahel võrrelda ja ühendada. Selleks on olemas tidyverse paketis join() käsud. join() käsud võtavad tabelis ühe või mitu tunnust ning proovib seda klapitada valitud tunnuse või tunnustega teises tabelis. Kõik read, kus on tunnuste kaupa täpselt sama väärtus on võimalik ühendada. Teistes pakettides kasutatakse siin merge() käsku, mis töötab sama loogikaga. Vaatame kõigepealt pildiülevaadet juhendis.
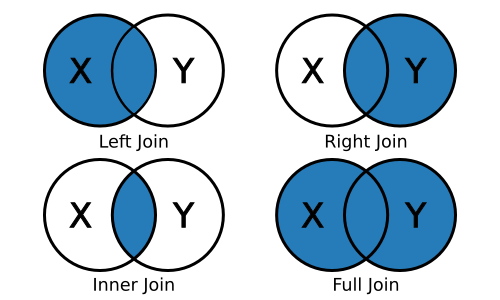
Pildi peal on kujutatud see ridadehulk, mis alles jääb. Täpsemalt öeldes, left_join() hoiab esimese tabeli terviklikuna. right_join() hoiab teise tabeli terviklikuna. inner_join() hoiab alles ainult kattuvad read. full_join() hoiab mõlemad tabelid terviklikuna. Ning anti_join() eemaldab teise tabeliga kattuvad read esimesest tabelist.
-left_join() - liidab vasakpoolse andmestiku külge need read, mis sobivad paremast. - right_join() - liidab parempoolse andmestiku külge need read, mis sobivad vasakust. - inner_join() - jätab alles ainult sobivad read kummastki - full_join() - jätab alles kõik read mõlemast tabelist, isegi kui ükski ei kattu. - anti_join() - töötab vastupidiselt ja eemaldab vasakust kõik read, mis ühtivad parempoolse tabeliga.
Hetkel on meil kaks tabelit. Käivita järgmised read, et neid näha.
## # A tibble: 157,632 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et välän
## 2 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et külmetas
## 3 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ja
## 4 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et taivast
## 5 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et satas
## 6 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et lummõ
## 7 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ütle
## 8 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et mullõ
## 9 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et uma
## 10 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et telefoni…
## # … with 157,622 more rows## # A tibble: 5,025 x 1
## word
## <chr>
## 1 minutaolisteks
## 2 veeres
## 3 samadeks
## 4 karkääksti
## 5 mihukeste
## 6 ii-ha-ha
## 7 milliseist
## 8 selleks
## 9 mõlemate
## 10 praeguseiks
## # … with 5,015 more rowsNüüd, liidame tabeli ‘laulusonad’ tabeliga ‘stopsonad’, kasutades inner_join() funktsiooni ja teeme seda “word” nimelise tulba kaudu, mis on mõlemas tabelis olemas. Tegelikult otsivad tidyverse join() käsud ka ise samanimelisi tulpasid ja kui neile täpsemaid juhiseid pole antud, siis ühendavad need. Kui me tegeleme uue andmestikuga on kasulik see alati välja kirjutada, et ei tekiks vigu.
## # A tibble: 67,862 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et ja
## 2 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et su
## 3 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et läbi
## 4 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et meil
## 5 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et ja
## 6 1994 1 NA Ummamuudu Kõnõtra… lyrics-ummamuudu-… 1 et ja
## 7 1994 2 NA Vennasko… Pille-R… lyrics-vennaskond… 1 et ja
## 8 1994 2 NA Vennasko… Pille-R… lyrics-vennaskond… 1 et kuhu…
## 9 1994 2 NA Vennasko… Pille-R… lyrics-vennaskond… 1 et on
## 10 1994 2 NA Vennasko… Pille-R… lyrics-vennaskond… 1 et on
## # … with 67,852 more rowsSee käsk niisiis leidis ainult kattuvad read kahes tabelis ning seeläbi jättis alles kõikidest lugudest ainult stopsõnad. Kui meid huvitavad näiteks asesõnade kasutus või sõnakordused, siis võimalik, et täpselt see meid huvitabki.
Me võime proovida neid kahte tabelit liita left_join() funktsiooni kaudu. Sellega küll ei muutu midagi, kuna liidetud tabel stopsonad sisaldabki ainult ühte tulpa, ning liidetud sõnad sulanduvad esimesse tabelisse.
## # A tibble: 157,632 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et välän
## 2 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et külmetas
## 3 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ja
## 4 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et taivast
## 5 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et satas
## 6 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et lummõ
## 7 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ütle
## 8 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et mullõ
## 9 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et uma
## 10 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et telefoni…
## # … with 157,622 more rowsEt kattuvad read ära markeerida võime teha stopsõnade tabelisse uue tulba, mis märgib, et on tõene, et see sõna on stopsõna.
Kui me nüüd ühendame tabelid left_join() kaudu, siis saame kaasa ka selle lisatulba.
## # A tibble: 157,632 x 10
## year rank votes artist song filename source language word onstopsona
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <lgl>
## 1 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et välän NA
## 2 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et külme… NA
## 3 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et ja TRUE
## 4 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et taiva… NA
## 5 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et satas NA
## 6 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et lummõ NA
## 7 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et ütle NA
## 8 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et mullõ NA
## 9 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et uma NA
## 10 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et telef… NA
## # … with 157,622 more rowsLihtsa väljundina võime näiteks kokku lugeda kumba on kui palju on kokku neid stopsõnu ja kui palju on muid sõnu (ehk neid, millel puudub informatsioon selle kohta, kas ta on stopsõna).
## # A tibble: 2 x 2
## onstopsona n
## <lgl> <int>
## 1 TRUE 67862
## 2 NA 89770Seal näeme, et teksti koguhulgast on stopsõnu veidi alla poole ja veidi üle poole on kõiki muid sõnu.
Samal põhimõttel võime ka leida kõige stopsõnaderikkama laulu.
laulusonad %>%
left_join(stopsonad2,by="word") %>%
group_by(artist,song) %>%
count(onstopsona) %>%
mutate(proportsioon=n/sum(n)) %>% # proportsiooni võime arvutada jagades loendatud arvu kõikide arvude summaga.
# kuna tabel on ikka veel gruppideks jaotatud, siis seda loetakse iga artisti-laulu sees
filter(onstopsona==TRUE) %>%
arrange(desc(proportsioon))## # A tibble: 781 x 5
## # Groups: artist, song [781]
## artist song onstopsona n proportsioon
## <chr> <chr> <lgl> <int> <dbl>
## 1 Hnd Kui Sa Vaid Saad TRUE 80 0.762
## 2 HND Kui sa vaid saad TRUE 80 0.762
## 3 Ott Lepland Siin me kokku saime TRUE 139 0.739
## 4 Nancy Keegi Teine TRUE 84 0.724
## 5 Jam Ei pea iial TRUE 145 0.721
## 6 HU? Mina Ise TRUE 90 0.714
## 7 Ines Ma ei tea mis juhtuks TRUE 188 0.709
## 8 Ott Lepland Otsides Ma Pean Su Jälle L… TRUE 61 0.709
## 9 Jam Ainus Tee TRUE 213 0.708
## 10 Vaiko Eplik Ja Eli… Armastus Päästab Maailma TRUE 69 0.704
## # … with 771 more rowsJa saame loo HND ‘Kui sa vaid saad’, millel on kolm neljandikku sõnu stopsõnad. Ainuüksi pealkiri koosnebki ainult stopsõnadest.
Proovi ise! Vali välja üks artist ja vaata milliseid stopsõnu nad kasutavad ja kui palju.
Enamasti on aga stopsõnade nimekiri kasulik, et need sõnad tekstist eemaldada. Näiteks võime võtta sama tabeli ja jätta alles ainult sõnad, mis ei ole stopsõnad. Selleks kasutame algusest tuttavat funktsiooni is.na(), mis kontrollib kas väärtus on puuduv. onstopsona == NA ei töötaks, kuna R-i jaoks on puuduvad väärtused erilised.
## # A tibble: 89,770 x 10
## year rank votes artist song filename source language word onstopsona
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <lgl>
## 1 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et välän NA
## 2 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et külme… NA
## 3 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et taiva… NA
## 4 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et satas NA
## 5 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et lummõ NA
## 6 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et ütle NA
## 7 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et mullõ NA
## 8 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et uma NA
## 9 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et telef… NA
## 10 1994 1 NA Ummamu… Kõnõt… lyrics-um… 1 et hamõ NA
## # … with 89,760 more rowsTäpselt sama teeb ka käsk anti_join(), mis jätab kõrvale kõik read, kus tunnused on sama väärtusega. Seda kasutame ka edaspidi.
## # A tibble: 89,770 x 9
## year rank votes artist song filename source language word
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et välän
## 2 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et külmetas
## 3 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et taivast
## 4 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et satas
## 5 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et lummõ
## 6 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et ütle
## 7 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et mullõ
## 8 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et uma
## 9 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et telefoni…
## 10 1994 1 NA Ummamuu… Kõnõtr… lyrics-ummamuud… 1 et hamõ
## # … with 89,760 more rowsSellega loendada kokku kõik sõnad, mis pole stopsõnad ja teha neist sagedustabeli.
## # A tibble: 18,164 x 2
## word n
## <chr> <int>
## 1 the 1033
## 2 you 1021
## 3 to 658
## 4 and 572
## 5 my 465
## 6 it 442
## 7 ref 374
## 8 täna 325
## 9 tean 296
## 10 hea 289
## # … with 18,154 more rowsNüüd näeme veel üht probleemi meie sõnaloendis. Paljud lood on ingliskeelsed ja seal on ka hulk sagedasi sõnu, mis samuti esiotsa pürgivad. Tabelis on olemas ka tunnus loo keele kohta ning selle abil võime piirduda edasi ainult eestikeelsete lugudega. Eestikeelsed lood on siin tähistatud rahvusvahelise tähisega ‘et’.
## # A tibble: 15,823 x 2
## word n
## <chr> <int>
## 1 ref 360
## 2 täna 325
## 3 tean 296
## 4 hea 289
## 5 aeg 280
## 6 päev 279
## 7 öö 264
## 8 taas 258
## 9 elu 257
## 10 jälle 226
## # … with 15,813 more rowsSaadud tabel on juba veidi informatiivsem
# A tibble: 15,823 x 2
# word n
# <chr> <int>
# 1 ref 360
# 2 täna 325
# 3 tean 296
# 4 hea 289
# 5 aeg 280
# 6 päev 279
# 7 öö 264
# 8 taas 258
# 9 elu 257
# 10 jälle 226ref viitab siin refräänile. muidu on sagedased päev, öö, taas, jälle, hea, aeg, täna, tean. Olenevalt sellest, mis meid huvitab, tasub meil stopsõnadenimekirja žanrile kohandada. Näiteks võime siin lisaks stopsõnadele tabelist välja võtta ka sõna ‘ref’.
laulusonad %>%
anti_join(stopsonad,by="word") %>%
filter(language=="et") %>%
count(word,sort=T) %>%
filter(!word %in% c("ref")) #Hüüumärk näitab eitust## # A tibble: 15,822 x 2
## word n
## <chr> <int>
## 1 täna 325
## 2 tean 296
## 3 hea 289
## 4 aeg 280
## 5 päev 279
## 6 öö 264
## 7 taas 258
## 8 elu 257
## 9 jälle 226
## 10 kord 214
## # … with 15,812 more rowsSalvestame selle tabeli samuti edasiseks kasutuseks.
5.4 Võrdlus teise korpusega
Me võime nüüd mõelda, kui tüüpiline meie laulusõnade korpus on võrreldes keelega üldisemalt. Nagu loengutes sai räägitud, on selleks kasulik vaadata sõnade suhtelist osakaalu korpuses, mitte absoluutarvu, kuna tekstikogude suurused võivad olla väga erinevad. Niisiis saame jagada leitud sõnade arvu kõikide sõnade arvu hulgaga, saades kätte millise proportsiooni see sõna tervikkorpusest moodustab.
## # A tibble: 15,822 x 3
## word n proportsioon
## <chr> <int> <dbl>
## 1 täna 325 0.00498
## 2 tean 296 0.00454
## 3 hea 289 0.00443
## 4 aeg 280 0.00429
## 5 päev 279 0.00428
## 6 öö 264 0.00405
## 7 taas 258 0.00395
## 8 elu 257 0.00394
## 9 jälle 226 0.00346
## 10 kord 214 0.00328
## # … with 15,812 more rowsMeil on võimalik seda proportsiooni võrrelda eesti ilukirjandusest tehtud korpusega. Ühe sellise korpuse kohta on sõnasageduste statistika saadaval siin. http://datadoi.ut.ee/handle/33/41. Loeme sisse sõnade sageduse info.
## Parsed with column specification:
## cols(
## word = col_character(),
## n_token = col_double(),
## n_docs = col_double()
## )Samamoodi nagu stopsõnade puhul, saame me nüüd ühendada need kaks tabelit.
## # A tibble: 15,822 x 6
## word n proportsioon n_token n_docs prop_ilukirj
## <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 täna 325 0.00498 2787 88 0.001
## 2 tean 296 0.00454 1552 84 0
## 3 hea 289 0.00443 5133 90 0.001
## 4 aeg 280 0.00429 3523 90 0.001
## 5 päev 279 0.00428 1899 90 0
## 6 öö 264 0.00405 784 82 0
## 7 taas 258 0.00395 1796 83 0
## 8 elu 257 0.00394 5460 90 0.001
## 9 jälle 226 0.00346 4416 88 0.001
## 10 kord 214 0.00328 3319 89 0.001
## # … with 15,812 more rowsVaadates nüüd väljatrükitud esikümmet võime näha, et suhtelise sageduse järgi on aeg, elu, jälle ja kord ikukirjanduses sagedasemad kui lauludes. Samas on öö, päev ja tean, vastupidi, sagedasemad just laulusõnades. Need erinevused võivad olla suuremad keskmise levikuga sõnade kohta.
Proovi vaadata ise mõne valitud sõna kohta, kuidas nende sagedused erinevad.
Kui meil on stopsõnad eemaldatud, võime ka vaadata kindlate artistide levinumaid sõnu, mis võiksid väljendada ka paremini nende lugude sisu. Niisiis, teeme sagedussõnastikud nende artistide kohta ja vaatame lähemalt.
laulusonad %>%
anti_join(stopsonad,by="word") %>%
filter(artist=="Põhja-Tallinn") %>%
count(word,sort=T)## # A tibble: 1,312 x 2
## word n
## <chr> <int>
## 1 aega 36
## 2 tean 26
## 3 maailm 25
## 4 saadab 23
## 5 koju 20
## 6 elu 19
## 7 hea 19
## 8 kallis 15
## 9 küsin 14
## 10 nõu 14
## # … with 1,302 more rowslaulusonad %>%
anti_join(stopsonad,by="word") %>%
filter(artist=="Ummamuudu") %>%
count(word,sort=T)## # A tibble: 62 x 2
## word n
## <chr> <int>
## 1 tunnen 14
## 2 mullõ 5
## 3 telefoninummõr 5
## 4 uma 5
## 5 ütle 3
## 6 lummõ 2
## 7 refr 2
## 8 satas 2
## 9 sis 2
## 10 utle 2
## # … with 52 more rows## # A tibble: 220 x 2
## word n
## <chr> <int>
## 1 ou 22
## 2 pa 10
## 3 öö 6
## 4 parap 6
## 5 täna 6
## 6 võtan 5
## 7 bonnie 4
## 8 cappuccino 4
## 9 clyde 4
## 10 hüppan 4
## # … with 210 more rowsProovi ise! Vali välja üks artist ning vaata nende enimkasutatud sõnu ilma stopsõnadeta.
5.5 Kordused laulu sees
Just laulusõnade puhul võib isegi artistidest huvitavamaks osutuda üksiklaulude vaatamine. Näiteks, kuna paljudel lauludel on refräänid (mõnikord on need küll andmetes ainult üks kord), siis võib oodata neil palju sõnakordusi.
Et teha sõnaloendeid laulude kohta, grupeerime tabeli kõigepealt laulude kaupa ning mõõdame sõnasagedusi sellel põhjal. Me võime siis vaadata näiteks kui suure osa kogu laulu sõnadest moodustab mõni konkreetne sõna.
laulusonad %>%
filter(language=="et") %>%
group_by(artist, song) %>%
count(word,sort=T) %>%
filter(!word %in% c("ref")) %>%
mutate(proportsioon=n/sum(n)) %>%
arrange(desc(proportsioon))## # A tibble: 63,710 x 5
## # Groups: artist, song [650]
## artist song word n proportsioon
## <chr> <chr> <chr> <int> <dbl>
## 1 Planeet Satelliidid satelliid… 36 0.621
## 2 The Tuberkuloited Tantsin Valssi na 72 0.319
## 3 Tuberkuloited & Urmas Voolpri… Tantsin valssi na 72 0.319
## 4 Kosmikud Öö Ei Lase Maga… magada 33 0.287
## 5 Mari-Leen 1987 o 60 0.275
## 6 HU? Elupõletaja ei 53 0.233
## 7 Anaconda Veel Veel Veel veel 31 0.218
## 8 Koer Maiu on piimaau… maiu 16 0.205
## 9 Koer Maiu on piimaau… on 16 0.205
## 10 Koer Maiu on piimaau… piimaauto 16 0.205
## # … with 63,700 more rowsSaame tulemuseks, et laulus satelliidid esineb sõn satelliidid 36 korda, see on üle poole sisust. Samas kui laulus Maiu on piimaauto, on nii maiu, on kui piimaauto 16 korda, ehk 20% kõigist sõnadest.
Proovi ise! Kui lugeda mitte proportsiooni järgi vaid koguarvult, siis mis sõna on kõige rohkem ühe laulu sees kordumas ja mis laulus?
Kui palju muutub tabel kui eemaldada stopsõnad?
5.6 Asukoht tekstis
Kasutades etteantud vahendeid on võimalik ka esitada küsimusi sõnade asukoha kohta. Näiteks, et kui laul kasutas sõna satelliidid nii palju kordi, siis kas seda laulu lõpus või alguses või läbivalt igal pool. Selleks saame kasutada käske group_by(), mutate() ja row_number(). Nimelt, et kui me vaatasime eelmises peatükis edetabeleid row_number() kaudu, siis nüüd võime kasutada seda ka sõnadel nende loomulikus järjekorras. Numbrid ühest kuni loo pikkuseni viitavad sõna asukohale tekstis.
Niisiis, saame iga laulu sees sõna asukoha grupeerides laulud eraldi ning lisades uue tulba row_number().
## # A tibble: 157,632 x 10
## # Groups: artist, song, year [999]
## year rank votes artist song filename source language word nr
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <int>
## 1 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et välän 1
## 2 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et külmet… 2
## 3 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et ja 3
## 4 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et taivast 4
## 5 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et satas 5
## 6 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et lummõ 6
## 7 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et ütle 7
## 8 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et mullõ 8
## 9 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et uma 9
## 10 1994 1 NA Ummamu… Kõnõtr… lyrics-ummam… 1 et telefo… 10
## # … with 157,622 more rowsKuna lood on erineva pikkusega, siis on võrdluse huvides ehk kasulik vaadata loo pikkust protsentidena. Selleks võime lisada ka loendi n() kaudu. mutate() võimaldab nii lisada mitu uut tunnust.
## # A tibble: 157,632 x 11
## # Groups: artist, song, year [999]
## year rank votes artist song filename source language word nr n
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <int> <int>
## 1 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et välän 1 52
## 2 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et külme… 2 52
## 3 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et ja 3 52
## 4 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et taiva… 4 52
## 5 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et satas 5 52
## 6 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et lummõ 6 52
## 7 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et ütle 7 52
## 8 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et mullõ 8 52
## 9 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et uma 9 52
## 10 1994 1 NA Ummamu… Kõnõ… lyrics-um… 1 et telef… 10 52
## # … with 157,622 more rowsJa kui meil on olemas nii rea number kui ridade arv võime välja arvutada sõna suhtelise asukoha. Lisame selleks tunnusele n ühe, et kõik tulemused oleks väiksem kui üks.
laulusonad %>%
group_by(artist,song,year) %>%
mutate(nr=row_number(), n=n()) %>%
mutate(asukoht=nr/(n+1))## # A tibble: 157,632 x 12
## # Groups: artist, song, year [999]
## year rank votes artist song filename source language word nr n
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <int> <int>
## 1 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et välän 1 52
## 2 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et külm… 2 52
## 3 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et ja 3 52
## 4 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et taiv… 4 52
## 5 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et satas 5 52
## 6 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et lummõ 6 52
## 7 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et ütle 7 52
## 8 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et mullõ 8 52
## 9 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et uma 9 52
## 10 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et tele… 10 52
## # … with 157,622 more rows, and 1 more variable: asukoht <dbl>Selle tulemuse põhjal saame arvutada, millisel kümnendikul loos sõna paikneb. Selleks võime korrutada asukoha, mis on nullist üheni, kümnega, et saada vahemiku 0-st 10-ni ja iga tulemuse ümardada alla, et kätte saada, millises kümnendikus sõna esines. Kui me jagame selle uuesti 10-ga saame kätte väärtused 0, 0.1, 0.2 … 0.9.
laulusonad %>%
group_by(artist,song,year) %>%
mutate(nr=row_number(), n=n()) %>%
mutate(asukoht=nr/(n+1)) %>%
mutate(asukoht_perc=floor(asukoht*10)/10)## # A tibble: 157,632 x 13
## # Groups: artist, song, year [999]
## year rank votes artist song filename source language word nr n
## <dbl> <dbl> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <int> <int>
## 1 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et välän 1 52
## 2 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et külm… 2 52
## 3 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et ja 3 52
## 4 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et taiv… 4 52
## 5 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et satas 5 52
## 6 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et lummõ 6 52
## 7 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et ütle 7 52
## 8 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et mullõ 8 52
## 9 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et uma 9 52
## 10 1994 1 NA Ummam… Kõnõ… lyrics-… 1 et tele… 10 52
## # … with 157,622 more rows, and 2 more variables: asukoht <dbl>,
## # asukoht_perc <dbl>Et me kasutame seda korduvalt võime jälle selle salvestada.
asukohad <- laulusonad %>%
group_by(artist,song,year) %>%
mutate(nr=row_number(), n=n()) %>%
mutate(asukoht=nr/(n+1)) %>%
mutate(asukoht_perc=floor(asukoht*10)/10)%>%
ungroup()Ja siis võime näiteks vaadata sõnu, mis palju kordi kordusid. Salvestame selle ka muutujana.
kordused <- laulusonad %>%
filter(language=="et") %>%
group_by(artist, song,year) %>%
count(word,sort=T) %>%
filter(!word %in% c("ref")) %>%
mutate(proportsioon=n/sum(n)) %>%
arrange(desc(proportsioon)) %>%
ungroup()Võtame 20 kõige enam ühe loo sees korratud sõna ja ühendame selle asukohtade tabeliga nii, et kattuvad nii artist, laul, aasta kui ka sõna. Salvestame selle tulemuse ja vaatame sisse.
asukohad_ja_kordused <- kordused %>%
filter(row_number()<21) %>%
inner_join(asukohad,by=c("artist","song","year","word"))Seejärel võime kokku lugeda, et kui palju neid sellel protsendil on.
Ülalolevast tabelist on küll raske ülevaadet saada, kuna see on pikk rodu numbreid ja mõned on puudu. R-is on tabelite pööramiseks hulk käske, tidyverse-is on selleks pivod_wider() ja pivot_longer(), mis teevad siis vastavalt tabeli laiaks horisontaalskaalal või pikaks vertikaalskaalal. pivot_wider() puhul määrame ära, millised tulbad jäävad nii-öelda paigale, id-tulpadeks, ja millised lahutame lahti.
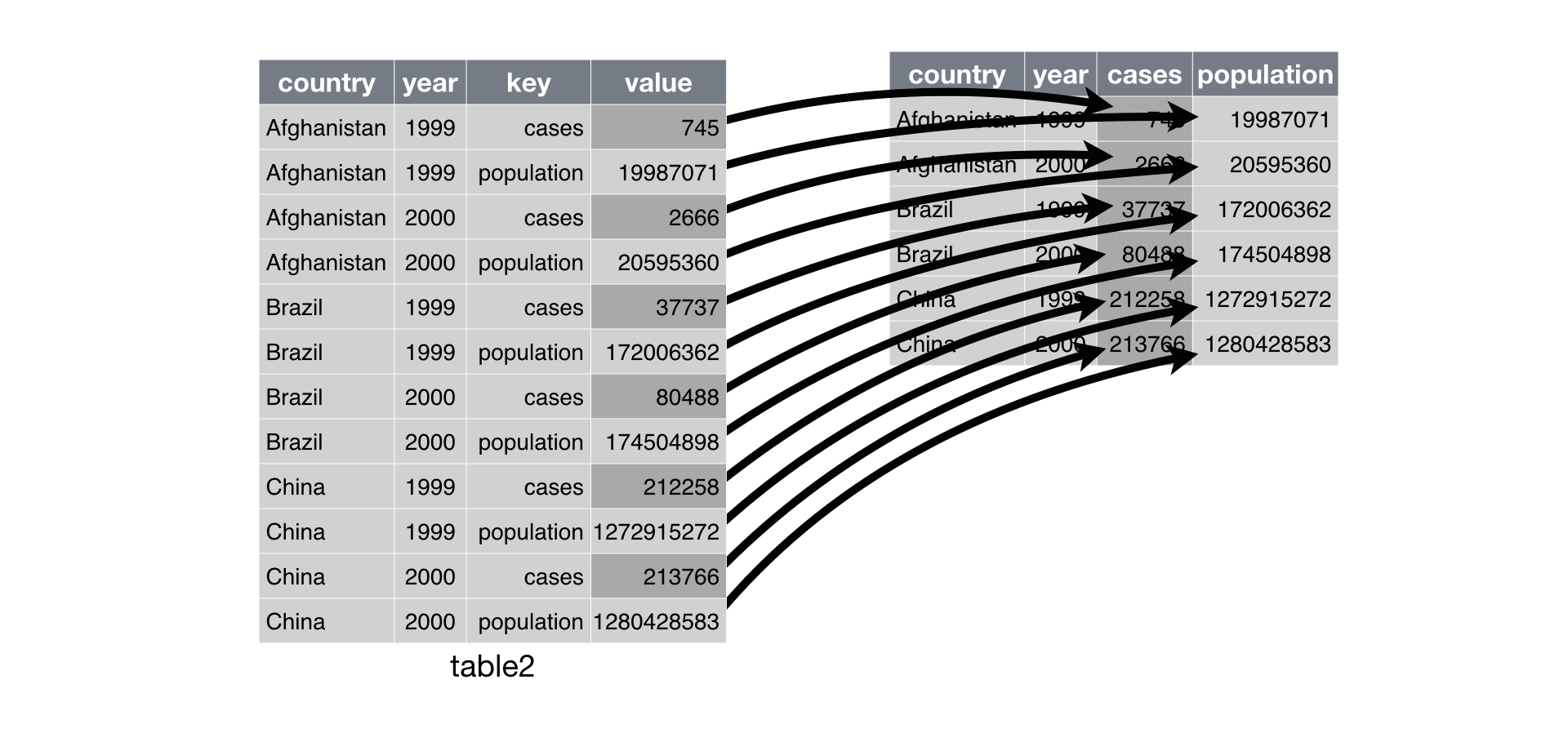
Laotame siis tabeli laiali ja vaatame, kus on need sagedasi korduvad sõnad.
kus_on_kordused %>%
arrange(asukoht_perc) %>%
pivot_wider(id_cols=c("artist","song","year","word"),names_from="asukoht_perc",values_from="n")## # A tibble: 20 x 14
## # Groups: artist, song, year, word [20]
## artist song year word `0` `0.1` `0.2` `0.3` `0.4` `0.5` `0.6` `0.7`
## <chr> <chr> <dbl> <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 Anaco… Veel… 2000 veel 7 8 NA NA NA NA NA 3
## 2 Beebi… Mend… 2011 mend… 4 8 9 9 10 8 10 5
## 3 HU? Elup… 2009 ei 1 NA 8 8 1 NA 12 6
## 4 Kosmi… Öö E… 2011 maga… 2 NA 4 4 1 1 5 5
## 5 Meie … Sini… 2003 sini… 2 2 2 2 2 4 2 2
## 6 Meie … Sini… 2003 vilk… 2 2 2 2 2 3 3 2
## 7 Meie … Sini… 2002 sini… 2 2 2 2 2 4 2 2
## 8 Meie … Sini… 2002 vilk… 2 2 2 2 2 3 3 2
## 9 N-Euro Tsak… 1999 tsha… 14 NA 7 7 10 2 5 3
## 10 Oreli… Valss 2011 laia… 3 2 2 2 2 3 5 2
## 11 Plane… Sate… 2012 sate… 5 1 5 4 6 1 3 6
## 12 Push … Musi 2000 musi 3 8 5 7 9 2 4 3
## 13 Mari-… 1987 2008 o NA 11 1 6 6 12 NA 10
## 14 Koer Maiu… 2004 maiu NA NA 3 1 NA 2 3 2
## 15 Koer Maiu… 2004 on NA NA 3 1 NA 2 2 3
## 16 Koer Maiu… 2004 piim… NA NA 2 2 NA 1 3 3
## 17 Mikk … Meie… 2015 pa NA NA 4 4 4 4 4 4
## 18 Gette… Rann… 2014 oo NA NA NA 12 NA NA 12 15
## 19 The T… Tant… 2000 na NA NA NA NA NA 3 22 11
## 20 Tuber… Tant… 2001 na NA NA NA NA NA 3 22 11
## # … with 2 more variables: `0.8` <int>, `0.9` <int>Siit tabelist on näha, et ‘sinine’ ja ‘vilkur’ on Meie Mehe loos Sinine vilkur üsna läbivalt. Samas ‘veel’ Anaconda laulus Veel Veel Veel ainult alguses ja lõpus. Beebilõust räägib ‘mentidest’ läbivalt, sõnad oo ja na on aga ainult laulude lõpus. Nende fraasidega võiks saada proovida läbi teiste lugude ka statistikat koguda. Siin tuleb küll silmas pidada, et laulusõnad on veidi erinevas formaadis ja mõnel neist ei ole korduv refrään taas uuesti kirjutatud, vaid on kasutatud lihtsalt sõna ref uuesti. Et täpsemalt analüüsi tuleks andmeid ka lähemalt ise vaadata.

Kui me tahame laia tabeli taas pikaks teha, kasutame funktsiooni pivot_longer(). pivot_longer() tahab teada, milliseid tulpi lahutada ja mis kahe uue tulba nimeks panna.
kus_on_kordused %>%
arrange(asukoht_perc) %>%
ungroup() %>%
pivot_wider(id_cols=c("artist","song","year","word"),names_from="asukoht_perc",values_from="n") %>%
mutate(year=as.character(year)) %>%
pivot_longer(cols=starts_with("0"), names_to="asukoht_perc", values_to="n")## # A tibble: 200 x 6
## artist song year word asukoht_perc n
## <chr> <chr> <chr> <chr> <chr> <int>
## 1 Anaconda Veel Veel Veel 2000 veel 0 7
## 2 Anaconda Veel Veel Veel 2000 veel 0.1 8
## 3 Anaconda Veel Veel Veel 2000 veel 0.2 NA
## 4 Anaconda Veel Veel Veel 2000 veel 0.3 NA
## 5 Anaconda Veel Veel Veel 2000 veel 0.4 NA
## 6 Anaconda Veel Veel Veel 2000 veel 0.5 NA
## 7 Anaconda Veel Veel Veel 2000 veel 0.6 NA
## 8 Anaconda Veel Veel Veel 2000 veel 0.7 3
## 9 Anaconda Veel Veel Veel 2000 veel 0.8 7
## 10 Anaconda Veel Veel Veel 2000 veel 0.9 6
## # … with 190 more rowsProovi ise! Vali mõni lugu ja sõna selles ning vaata, mis asukohtadel ta esineb.
5.7 Sõnastik
- %>% - vii andmed järgmisesse protsessi
- unnest_tokens() - võtab tekstijupi ja jupitab selle mingil alusel ja paneb iga jupi eraldi reale.
- left_join() - liidab vasakpoolse andmestiku külge need read, mis sobivad paremast.
- right_join() - liidab parempoolse andmestiku külge need read, mis sobivad vasakust.
- inner_join() - jätab alles ainult sobivad read kummastki
- full_join() - jätab alles kõik read mõlemast tabelist, isegi kui ükski ei kattu.
- anti_join() - töötab vastupidiselt ja eemaldab vasakust kõik read, mis ühtivad parempoolse tabeliga.
- group_by() - grupeeri andmestik mõne tunnuse alusel
- ungroup() - vii andmestik grupeerimata kujule
- pivot_wider() - vii tabel laiaks
- pivot_longer() - vii tabel pikak
5.8 Harjutusülesanded
Millised olid levinuimad sõnad Vaiko Epliku sõnavaras?
Millised olid levinuimad sõnad Vaiko Epliku sõnavaras kui eemaldada ka stopsõnad?
Milline oli levikult kolmeteistkümnes sõna kõigis eestikeelsetes tekstides?
Mitu sõna esines kõigil 25-l aastal?
Leia sõnad, mida korrati kõige rohkem laulu teises pooles.